Latent Dirichlet allocation (LDA) on Reddit Data
So I did this neat LDA project for a course in Uni and proudly listed it in my resume. (Note: I did end up copying most of the code from a blog post I found at the time.) Fastforward to an interview and out of all the listed projects on my resume, they happened to only ask me about that one.
“Can you tell us more about what you did for the LDA project?” - Interviewer
“I’m not so sure.. I just used a function from the scikit-learn library” - Me
Yea.. not good….
I did email them back with an explanation and more details on the project but I think the damage was done. I’d like to revisit that project, run it on new data, and hopefully uncover something interesting to share with everyone.
Background
Before we start, Its worth going over what LDA is and where its used:
Latent Dirichlet Allocation
Now there are a number of blog posts out there that describe LDA really well:
Here’s my take:
Latent Dirichlet Allocation is an unsupervised clustering algorithm.
It is often used for topic modelling on documents to:
- uncover hidden themes in the documents
- then classify the documents into those themes
- use this new information to help search/sort/explore the documents
Lets say you are searching up a guide to cook meals for your workouts and you use the search query “gym muscle building food”. A search engine might find and return the document “Meal-Prep for bulking”. One reason it might have found it is because the document has been preprocessed and categorized with the topics gym and food.
That preprocessing step was likely done with an LDA process.
Lets say we have the following documents and a list of the words in each document (sorted by frequency):
| document | words (most frequent first) |
|---|---|
| “beach body.txt” | {word20:muscle, word23:body, word30:gym,… } |
| “meal prep for beginners.txt” | {word4:beginner, word54:Weight, word1:Hello … } |
| “meal prep for bulking.txt” | {word4:cook, word18:chicken, word55:excercise, … } |
| “meal prep for bulking.txt” | {word4:cook, word18:chicken, word55:excercise, … } |
| “meal prep for bulking.txt” | {word4:cook, word18:chicken, word55:excercise, … } |
can you tell what’s been on my mind lately?
Lets say there are 3 hidden topics amongst the documents… Lets figure out the probabilities for each word belonging to each topic.
| word20:muscle | word4:cook | word18:chicken | … | |
|---|---|---|---|---|
| Topic1:(could be gym) | 0.4 | 0.1 | 0.14 | |
| Topic1:(could be fat) | 0.04 | 0.64 | 0.25 | |
| Topic1:(could be protein) | 0.3 | 0.02 | 0.7 |
If we had the above information, we could pick the top 10 (probability) words for each topic and use that to categorize documents by Topics.
So.. How do we get there?
The Algorithm:
-
First go through each document and assign each word randomly to one of your k (3 in the example above) topics.
- For each document again go through each word and calculate:
- Frist \(p(t \vert d)\) (excluding the current word) to get the number of words that belong to topic t for a document d.
- Then, \(p(w \vert t)\) to get how many documents are in a topic t since it has the word w.
- Update \(p(w \vert t,d)\) by \(p(w \vert t,d) = p(t \vert d)*p(w \vert t)\)
Repeatedly execute the above algorithm to finally get to that table above.
The Dataset - Reddit
You’ve all heard of reddit.. If you havnt come across it on a browser perhaps you’ve come by the tiktoks that just text-to-speech spicy reddit posts.
 You tried to click on it didnt you?
You tried to click on it didnt you?
I got the data from : https://files.pushshift.io/reddit/
The 2018-10 data is 3.5GB compressed (in zst format) and 41GB extracted. The 2022-07 data is 10GB condensed and 142GB extracted. (this will be important later.)
Now here is the reason why I had a month of delay actually posting this blog. I tried to use PySpark to read the condensed JSON. I got some errors… I tried to debug.. and went down a rabbit hole of errors.. A month later, during a long weekend, realized I can just unzstd (extract) the file and then proceed to read the JSON using Spark.
I’m not entirely sure what the performance benefit of running a local instance of Spark is, but I am slightly familiar with the library. Using SparkSQL and running a query like:
1
2
topScoringTitles = spark.sql("SELECT author, author_id, author_created_utc, subreddit,
subreddit_subscribers, title, score FROM Submissions ORDER BY score DESC LIMIT 50")
took 5 minutes, until I adjusted a few PySpark submit arguments (the no. executor cores and amount of allocation memory) and brought the time down to a 1 minute.
Anyway here’s some useless facts I found:
The top 3 scoring submissions of October 2018 had the following titles:
- Kids in Elementary school hold a surprise party for their beloved school custodian.
- Tried to take a panoramic picture of the Eiffel Tower today, it went surprisingly well!
- Trump boards Air Force One with toilet paper stuck to his shoe.
{kind=link}
The Algorithm:
The 25 most popular subreddits were first chosen. The top 1000 highest scoring headlines from each subreddit were then collected. These headlines were first preprocessed and then concatenated to create documents for each Subreddit. Finally the LDA process was run where 15 hidden underlying topics were discovered.
Preprocessing:
- Headlines were tokenized, lowercased and filtered of punctuation and stop words.
- Porter Stemmer was used to change words to first person and present tense words. (Eg. Apples –> Apple)
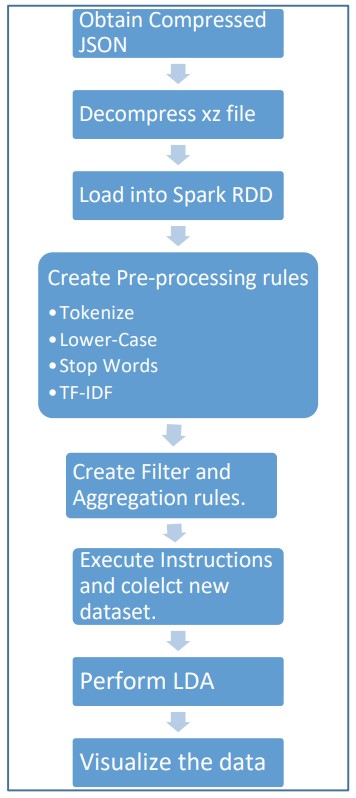
Hyper-Parameters:
There are many hyper-parameters to be considered while executing LDA.
- Topics = 15
- Titles from one Subreddit chosen to be the document
- The use of Porter Stemmer instead of Snowball Stemmer in pre-processing
- Words that appear in less than 4 documents (or subreddits) are excluded
- Words that appear in more than 80% of the documents are excluded
- Only the first 1,000,000 tokens are retained after above steps
LDA
I used the gensim library to run the LDA process.
First I had to create a dictionary of the documents:
1
dictionary = gensim.corpora.Dictionary(ppdFrames)
I then filtered the words in each document according the hyper-parameters listed above.
1
dictionary.filter_extremes(no_below=4, no_above=0.8, keep_n=1000000)
And finally:
1
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics=15, id2word=dictionary, passes=3, workers=2)
Results:
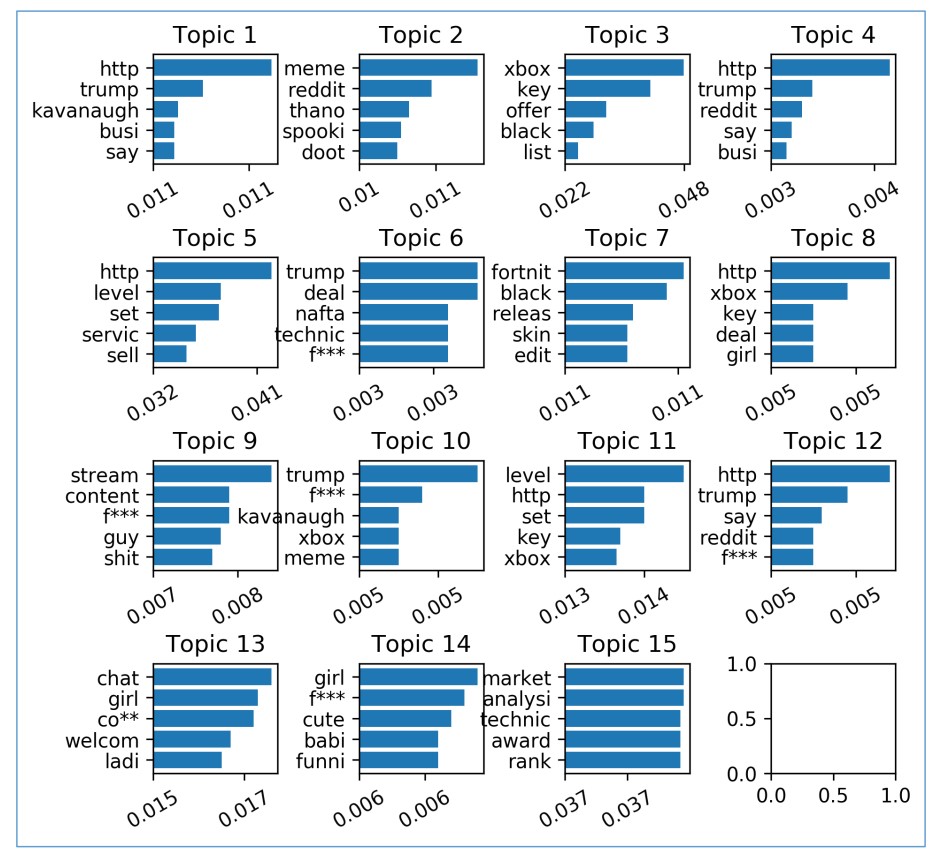 Words in relation to Topics
Words in relation to Topics
Topics are still abstract concepts here and only hold numbers at the moment. However, we can imagine these topics to be centered around some loose topic. Topics 15 has high values for words revolving around finance. Topics 14 and 15 revolve around nsfw material. One interesting observation is that the word ‘trump’ is distributed across the greatest number of topics. This is expected, since mentions of ‘Trump’ in media were very popular at the time.
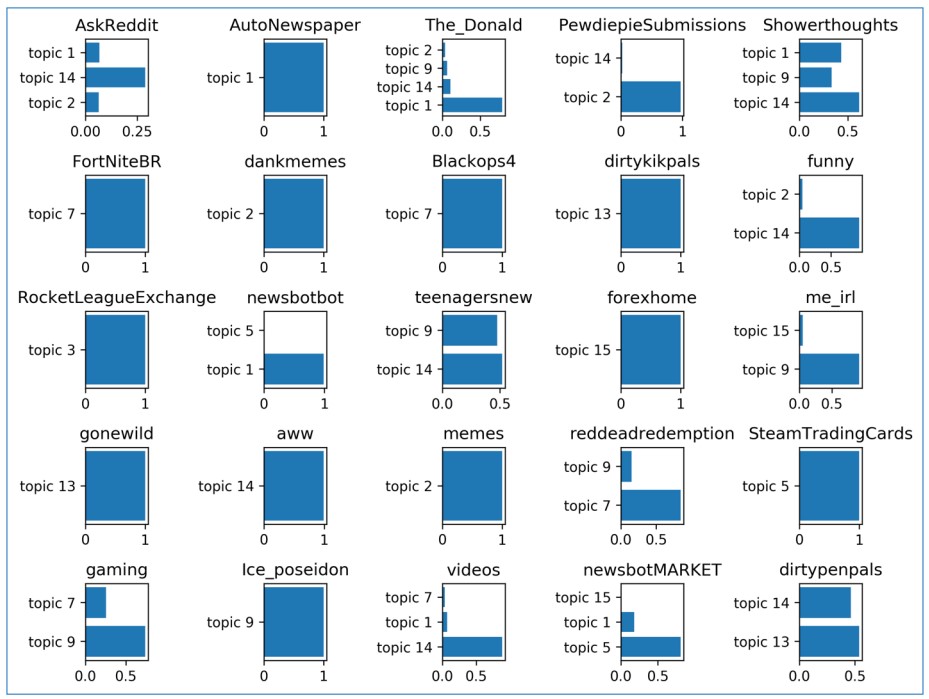 Top 25 Subreddits and Topics most likely to be assigned to them
Top 25 Subreddits and Topics most likely to be assigned to them
Topics 4, 6, 8, 10 and 12 were not used. This is likely do to the most popular subreddit consisting of random headlines from a ‘ask any question’ subreddit ‘AskReddit’. There are also at least 6 subreddits where 90% of the contributions are by bots. These bots have created headlines with ‘http’, ‘trump’ and ‘market’, all of which are in the Topics not present and describe very general topics in the news today. More stringent exclusion of words in the preprocessing can help derive more meaningful results from those topics.
Another Interesting thing is that since my 2017 dataset is from October, the Skull Trumpet meme was doing its rounds. Topic 2 showcases its popularity especially when the topic is assigned back to subreddits like: PewdiepieSubmissions, dankmemes, funny and memes.
New Data:
Alright, at the time of writing the RS_2022-07 file is 142GB in size. I havnt set up a cluster in order to read that json file so I will save that for a later date.
Conclusion:
Reddit is ripe with tough data analytics projects. There are still many combinations of hyper-parameters to experiment with and more room for stronger data pre-processing. It is rather difficult to say how many hidden features should exist.
Sources:
-
D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” The Journal of Machine Learning Research, vol. 3, pp. 993–1022, Mar. 2003.
-
Jason Baumgartner, “pushshift.io – learn about big data and social media ingest and analysis.” [Online] Available: https://pushshift.io